GLM-4.41V thinking: Advancing the understanding and reasoning of universal multimodal
Vision Models (VLM) play a crucial role in today’s intelligent systems by learning about visual content in detail. The complexity of multimodal intelligent tasks has grown, from scientific problem solving to the development of autonomous agency. The current demand for VLM far exceeds simple visual content perception, and the focus on advanced reasoning is increasing. Although recent works have shown that long-term reasoning and scalable RL significantly enhance LLMS problem-solving capabilities, current efforts are focused primarily on specific areas to improve VLM reasoning. Currently, the open source community lacks a multimodal inference model that outperforms traditional non-thinking models across various tasks.
Researchers from Zhipu AI and Tsinghua University proposed the GLM-4.1V thinking, a VLM designed to improve understanding and reasoning for universal multimodality. The method then introduces enhanced learning through course sampling (RLC) to unlock the full potential of the model, which can be improved in STEM problem solving, video comprehension, content recognition, encoding, basics, GUI-based agents, and long-term document understanding. The researchers’ open source GLM-4.1V-9B mindset sets a new benchmark in similar-sized models. It also offers competition, in some cases, compared to proprietary models such as GPT-4O (such as long-term document understanding and STEM reasoning).


GLM-4.1V thinking contains three core components: vision encoder, MLP adapter and LLM decoder. It uses AIMV2-tuge as the visual encoder and GLM as the LLM, replacing the original 2D convolution with 3D convolution for temporary downsampling. The model integrates 2D ropes to support arbitrary image resolution and aspect ratios, and handles extreme aspect ratios of 200:1 and high resolutions over 4K. The researchers extended the rope to 3D ropes in LLM to improve spatial understanding in multimodal environments. For time modeling in video, add a time index token after each frame token, the timestamp is encoded as a string to help the model understand the real-world time gap between frames
During the pre-training period, researchers used a variety of data sets to combine large academic corpus with knowledge-rich image text data. By including plain text data, the core language functionality of the model is preserved, thus better through @k performance than other advanced previously trained base models of similar size. The supervised fine-tuning phase transforms the basic VLM into one capable of using curated long-term cot cots that can use cross-COT inference, such as STEM problems, and non-verifiable tasks such as the following instructions. Finally, the RL stage adopts a combination of RLVR and RLHF to conduct large-scale training in all multimodal fields, including STEM problem solving, grounding, optical feature recognition, GUI agents, etc.
GLM-4.1V-9B thinks about all competing open source models that exceed 10B parameters in general VQA tasks, covering monolithic and multi-image settings. It achieves the highest performance on challenging STEM benchmarks, including MMMU_VAL, MMMU_PRO, VIDEOMMMU and AI2D. In OCR and Chart fields, the model sets new state-of-the-art scores on ChartQapro and ChartMuseum. For long-term documentation understanding, GLM-4.1V-9B thinking has outperformed all other models on mmlongbench while building new latest state-of-the-art GUI proxy and multi-mode coding tasks. Finally, the model shows strong video comprehension performance, trumping video, MMVU and MotionBench benchmarks.
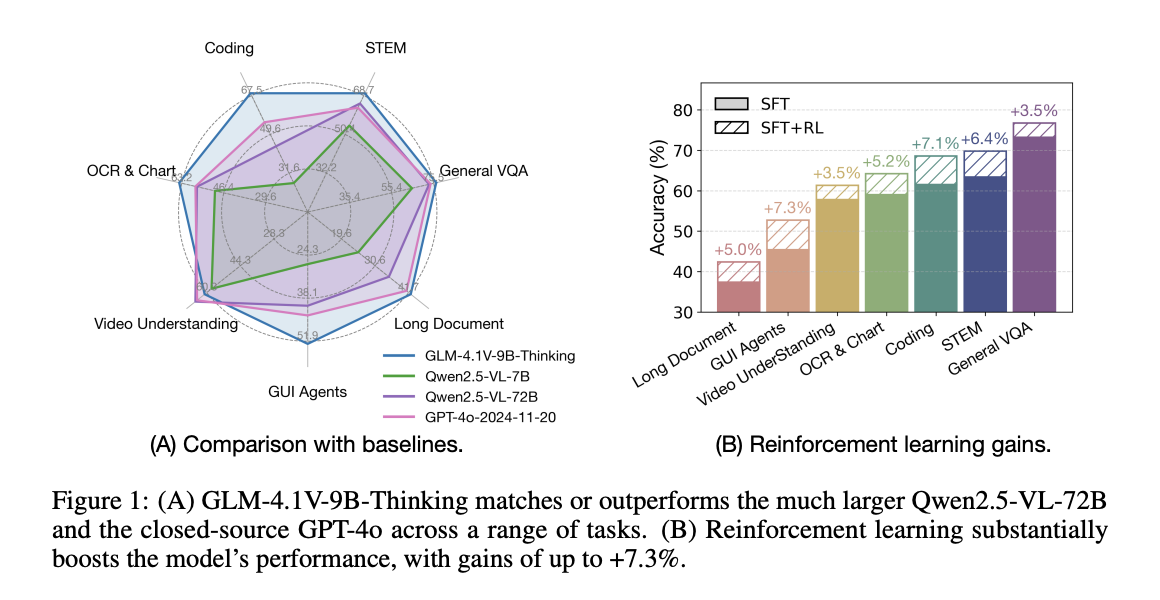
In short, the researchers introduced the GLM-4.1V thinking, which represents a step towards universal multimodal reasoning. Its 9B parameter model is better than larger models, such as models with more than 70b parameters. However, there are still some limitations, such as the quality of reasoning through RL, instability during training, and inconsistencies in complex cases. Future developments should focus on improving supervision and evaluation of model inference and through reward models evaluating intermediate inference steps while detecting hallucinations and logical inconsistencies. Furthermore, exploring strategies for reward hacking in preventing subjective assessment tasks is crucial to achieving universal intelligence.
Check Paper and Github page. All credits for this study are to the researchers on the project.
| Sponsorship Opportunities |
|---|
| Attract the most influential AI developers worldwide. 1M+ monthly readers, 500K+ community builders, unlimited possibilities. [Explore Sponsorship] |

Sajjad Ansari is a final year undergraduate student from IIT Kharagpur. As a technology enthusiast, he delves into the practical application of AI, focusing on understanding AI technology and its real-world impact. He aims to express complex AI concepts in a clear and easy way.


