Getting started with Mirascope: Use LLM to delete semantic duplications
Mirascope is a powerful and user-friendly library that provides a unified interface for working with a wide range of large language model (LLM) providers including OpenAI, Anthropic, Mistral, Google, Google (Gemini and Vertex AI), Groq, Groq, Groq, Cohere, Cohere, Litellm, Azure AI, and Amazon Bedrock. It simplifies everything from text generation and structured data extraction to building complex AI-driven workflows and proxy systems.
In this guide, we will focus on using Mirascope’s OpenAI integration to identify and delete semantic duplicates (entries with different wording but with the same meaning) from the customer comment list.
Install dependencies
pip install "mirascope[openai]"Openai key
To obtain the OpenAI API key, access and generate a new key. If you are a new user, you may need to add billing details and pay a minimum of $5 to activate API access.
import os
from getpass import getpass
os.environ['OPENAI_API_KEY'] = getpass('Enter OpenAI API Key: ')Define a list of customer reviews
customer_reviews = [
"Sound quality is amazing!",
"Audio is crystal clear and very immersive.",
"Incredible sound, especially the bass response.",
"Battery doesn't last as advertised.",
"Needs charging too often.",
"Battery drains quickly -- not ideal for travel.",
"Setup was super easy and straightforward.",
"Very user-friendly, even for my parents.",
"Simple interface and smooth experience.",
"Feels cheap and plasticky.",
"Build quality could be better.",
"Broke within the first week of use.",
"People say they can't hear me during calls.",
"Mic quality is terrible on Zoom meetings.",
"Great product for the price!"
]These reviews capture key customer sentiments: praise sound quality and ease of use, complaints about battery life, building quality and call/microphone issues, and positive comments on value for money. They reflect common topics found in actual user feedback.
Define Pydantic schema
This pydantic model defines the structure of responses to semantic deduplication tasks on customer reviews. This pattern helps build and validate the output of a language model responsible for cluster or natural language input in repetitive data (e.g., user feedback, error reports, product reviews).
from pydantic import BaseModel, Field
class DeduplicatedReviews(BaseModel):
duplicates: list[list[str]] = Field(
..., description="A list of semantically equivalent customer review groups"
)
reviews: list[str] = Field(
..., description="The deduplicated list of core customer feedback themes"
)Define mirascope @openai.call for semantic deduplication
This code defines the semantic deduplication feature using Mirascope’s @OpenAi.Call Decorator, which integrates seamlessly with OpenAI’s GPT-4O model. The DEDUPLICATE_CUSTOMER_REVIEWS function lists the customer comment list and uses a structured prompt defined by @prompt_template Decorator to guide the LLM to recognize and group comments semantically similar.
System messages instruct the model to analyze the meaning, tone, and intention behind each comment, and even if the wording is different, the meaning of conveying the same feedback. The functionality expects structured responses to be consistent with the DeduplicatedReviews Pydantic model, which includes two outputs: a unique, a list of deleted comment sentiments, and a list of grouped duplicates.
The design ensures that the output of the LLM is both accurate and readable, which is ideal for customer feedback analysis, investigation of deduplication or product review clustering.
from mirascope.core import openai, prompt_template
@openai.call(model="gpt-4o", response_model=DeduplicatedReviews)
@prompt_template(
"""
SYSTEM:
You are an AI assistant helping to analyze customer reviews.
Your task is to group semantically similar reviews together -- even if they are worded differently.
- Use your understanding of meaning, tone, and implication to group duplicates.
- Return two lists:
1. A deduplicated list of the key distinct review sentiments.
2. A list of grouped duplicates that share the same underlying feedback.
USER:
{reviews}
"""
)
def deduplicate_customer_reviews(reviews: list[str]): ...The following code executes the DEDUPLICATE_CUSTOMER_REVIEWS function using the customer comment list and prints the structured output. First, it calls the function and stores the result in the response variable. To ensure that the output of the model is in line with the expected format, it uses assertion statements to verify that the response is an instance of the DewuplicatedReviews Pydantic model.
Once verified, it will print the result of duplicate data in both sections. The first section is marked “✅Different Customer Feedback”, showing a list of the unique comments that the model determines. The second part “🌀 Grouping Repeat” lists the comment clusters that are considered semantically equivalent.
response = deduplicate_customer_reviews(customer_reviews)
# Ensure response format
assert isinstance(response, DeduplicatedReviews)
# Print Output
print("✅ Distinct Customer Feedback:")
for item in response.reviews:
print("-", item)
print("n🌀 Grouped Duplicates:")
for group in response.duplicates:
print("-", group)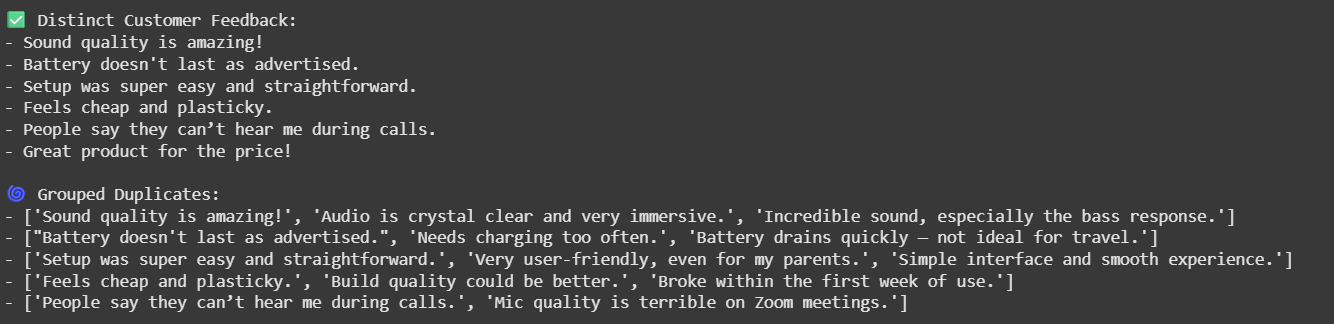
The output shows a clean summary of customer feedback by grouping semantically similar comments. Different customer feedback sections highlight key insights, while grouped repetition sections capture different wordings of the same point of view. This helps eliminate redundancy and makes feedback easier to analyze.
View the full code. All credits for this study are to the researchers on the project.
Ready to connect with 1 million+ AI development/engineers/researchers? See how NVIDIA, LG AI Research and Advanced AI companies leverage Marktechpost to reach target audiences [Learn More]

I am a civil engineering graduate in Islamic Islam in Jamia Milia New Delhi (2022) and I am very interested in data science, especially neural networks and their applications in various fields.


