DSRL: A potential spatially enhanced learning approach to adapt to real-world proliferation policies
Introduction to learning-based robotics
Robot control systems have made significant progress by replacing manually coded instructions with data-driven learning. Modern robots do not rely on explicit programming, but learn by observing actions and imitating them. This form of learning is often based on behavioral cloning, allowing robots to function effectively in a structured environment. However, transferring these learned behaviors to dynamic realities remains a challenge. Robots not only need to repeat actions, but also need to adapt and refine their responses when facing unfamiliar tasks or environments, which is crucial to achieving generalized autonomous behavior.
Traditional behavioral cloning challenges
One of the core limitations of robot policy learning is its reliance on pre-collected human demonstrations. These demonstrations are used to develop initial policies through supervised learning. However, when these policies cannot be generalized or accurately executed in new settings, additional demonstrations are required to retrain them, which is a resource-intensive process. The inability to use the robot’s own experience to improve policies can lead to less adaptability. Reinforcement learning can promote autonomous improvement; however, its inefficiency in sample and its dependence on direct access to complex policy models make it unsuitable for many real-world deployments.
Limitations of current diffusion RL integration
Various approaches attempt to combine proliferation-based policies with enhanced learning to refine robot behavior. Some efforts focus on modifying early steps of the diffusion process or applying additive adjustments to the strategy output. Others attempt to optimize actions by evaluating the expected rewards in the downgrade step. Although these methods improve in simulation environments, they require extensive calculations and direct access to policy parameters, which limits their usefulness to black boxes or proprietary models. Furthermore, they struggle with the instability arising from backpropagation through multi-step diffusion chains.
DSRL: A framework for potential noise strategy optimization
Researchers at UC Berkeley, University of Washington and Amazon have introduced a technology called diffusion steering through enhanced learning (DSRL). This approach converts the adaptation process from modifying the policy weights to potential noise used in the optimized diffusion model. Instead of generating actions from a fixed Gaussian distribution, DSRL trains a secondary strategy that selects input noise in a way that turns the final action toward the ideal result. This allows for enhanced learning to effectively adjust behavior without changing the basic model or requiring internal access.

Potential noise space and policy decoupling
The researchers reorganize the learning environment by mapping the original action space to a potential noise space. In this conversion setting, actions are selected indirectly by selecting potential noise that will be generated by the diffusion strategy. By treating noise as an action variable, DSRL creates a reinforcement learning framework that uses only its forward output, running entirely outside of the basic strategy. This design makes it suitable for real-world robotic systems that are accessible only with black boxes. A strategy for selecting potential noise can be trained using standard participant critical methods, thereby avoiding the computational cost of backpropagation through the diffusion step. This method allows for online learning through real-time interaction and offline learning from pre-collected data.
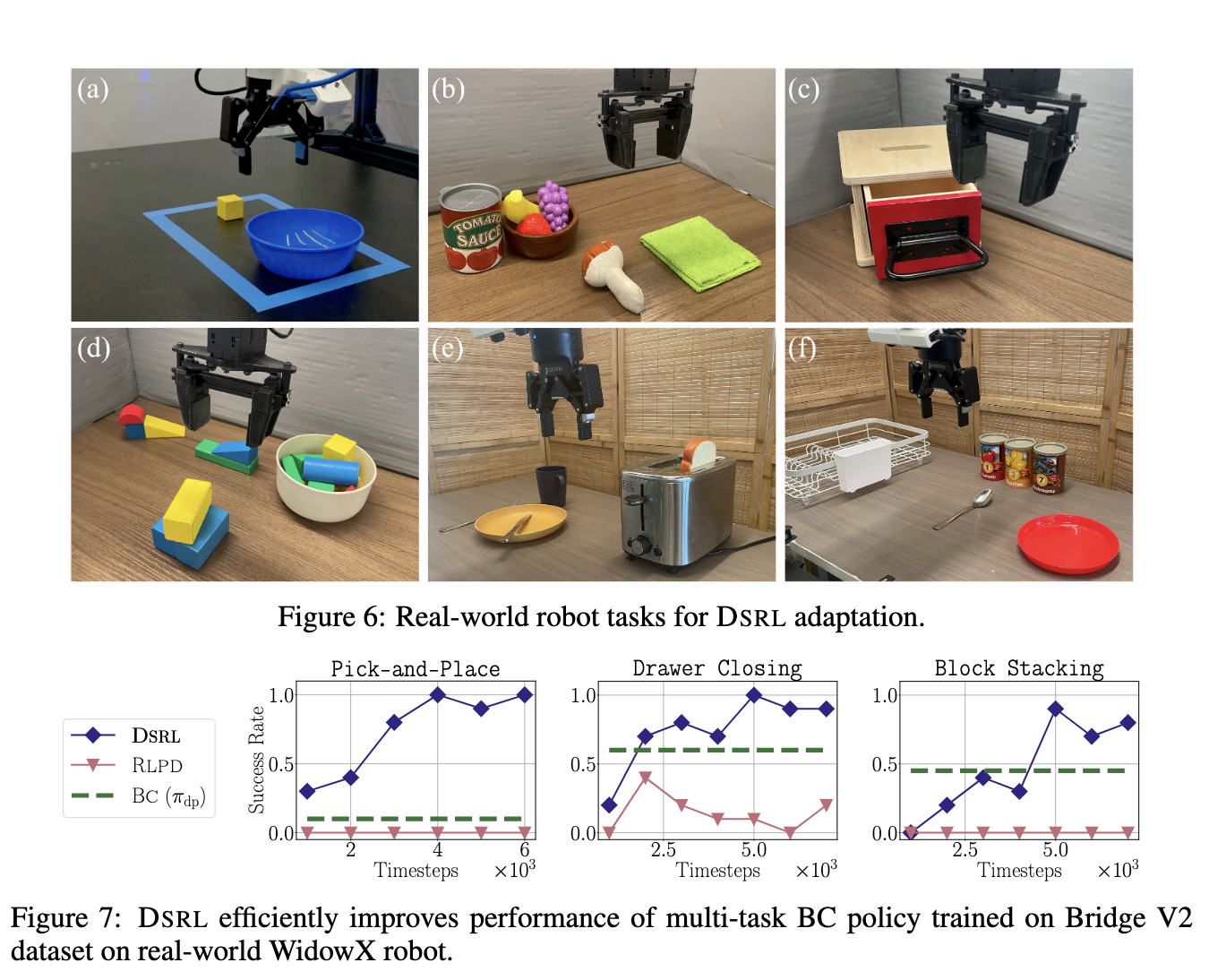
Experienced results and practical benefits
The proposed method shows a significant improvement in performance and data efficiency. For example, in a realistic robotics task, DSRL improves task success rate from 20% to 90% in less than 50 episodes of online interaction. This represents more than four times the performance of the minimum data. The method also tests a generalist robot strategy called π₀, and DSRL can effectively enhance its deployment behavior. These results are implemented without modifying the basic diffusion policy or accessing its parameters, thus demonstrating the practicality of the approach in a restricted environment such as API-Forly deployment only.
in conclusion
In summary, the study addresses the core issues of robot policy adaptation without relying on extensive retraining or direct model access. By introducing a potential noise steering mechanism, the team developed a lightweight and powerful tool for real-world robotic learning. The strength of this approach lies in its efficiency, stability and compatibility with existing diffusion models, which makes it an important step in deploying adaptive robot systems.
Check Paper and project pages. All credits for this study are to the researchers on the project. Also, please feel free to follow us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Nikhil is an intern consultant at Marktechpost. He is studying for a comprehensive material degree in integrated materials at the Haragpur Indian Technical College. Nikhil is an AI/ML enthusiast and has been studying applications in fields such as biomaterials and biomedical sciences. He has a strong background in materials science, and he is exploring new advancements and creating opportunities for contribution.



