Stateless Introduction Tower+: A unified framework for high-fidelity translation and guidance in multilingual LLMS
Large language models have made progress in machine translation, leveraging a large-scale training corpus to translate dozens of languages and dialects while capturing subtle linguistic nuances. However, fine-tuning of translation accuracy of these models often undermines their tracking and conversational skills, and a wide range of uses versions struggles to meet professional loyalty standards. The ability to balance precise, culturally conscious translation with processing code generation, problem-solving and user-specific formats remains challenging. The model must also preserve term consistency and adhere to format guidelines for various audiences. Stakeholders need systems that can dynamically adapt to domain needs and user preferences without sacrificing fluency. Benchmark scores such as WMT24++ cover 55 language variants, while IFEVAL’s 541 instructions highlight the gap between professional translation quality and universal use versatility, creating a critical bottleneck for Enterprise deployment.
Current methods of tailoring language models to improve translation accuracy
Various ways to tailor language models have been explored. Fine-tuning pre-trained large language models for parallel corpus have been used to improve the adequacy and fluency of translated texts. Meanwhile, continuing pre-cultivation with the combination of monolingual and parallel data will enhance multilingual fluency. Some research teams complement the training by conducting enhanced learning training from human feedback to combine output with quality preferences. Proprietary systems such as GPT-4O and Claude 3.7 have proven leading translation quality, with open weight adaptations including Tower V2 and Gemma 2 models reaching parity or exceeding closed models in some language scenarios. These strategies reflect on ongoing efforts to meet the dual requirements of translation accuracy and broad language competence.
Introduction Tower+: Unified Training for Translation and General Language Tasks
Researchers at Unbabel, Telecomunicações, Instituto Superior Técnico, Lisboa University (Ellis Unit in Lisbon) and MICS, Central Supélec, Paris-Saclay University Tower+a set of models. The research team designed variants of multiple parameter scales, 2 billion, 9 billion and 72 billion designs to explore the trade-off between translation professional and general utility. By implementing a unified training pipeline, the researchers aim to position the tower+ model on the Pareto border, both achieving high conversion performance and powerful general capabilities without sacrificing another function. This approach utilizes architecture to balance the specific needs of machine translation with the flexibility required for dialogue and teaching tasks, thus supporting a range of application scenarios.
Tower+training pipeline: preprocessing, supervised adjustments, preferences and RL
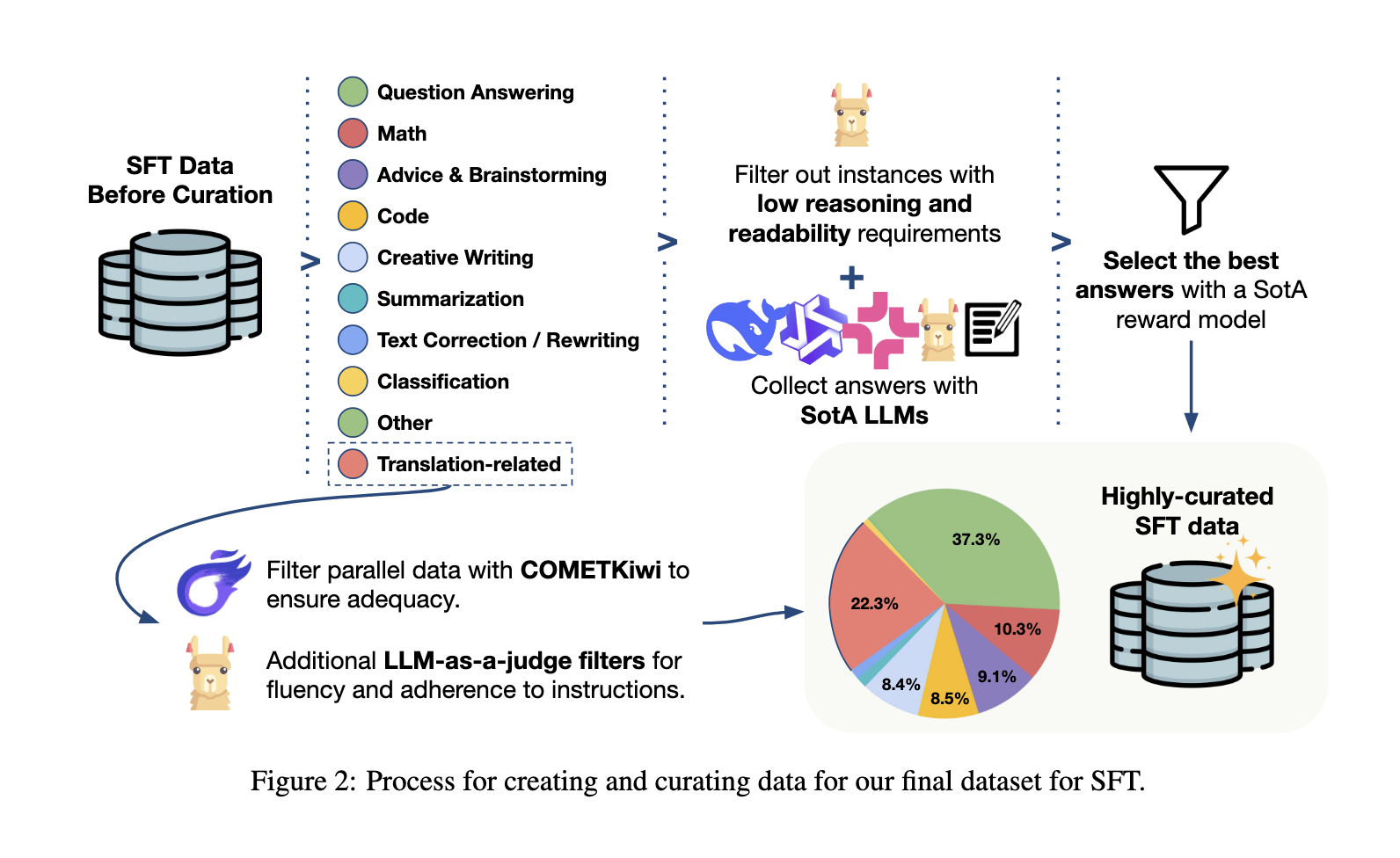
The training pipeline begins with carefully curated data that continues to carefully review, including monolingual content, filtered parallel sentence formats as translation instructions, and a small number of instruction examples. Next, supervised fine-tuning perfects the model through a combination of translation tasks and schemes that follow various instructions, including the effects of code generation, mathematical problem solving, and questioning. The preference optimization phase follows, adopting weighted priority optimization and group-related policy updates for group signals and human-edited translation variant training. Finally, strengthening learning with verifiable rewards can enhance precise adherence to the transformation guide and use regular-based checks and preference annotations to refine the model’s ability to follow clear instructions during the translation process. The combination of preprocessing, supervised alignment and reward-driven updates strike a strong balance between professional translation accuracy and multi-functional language proficiency.
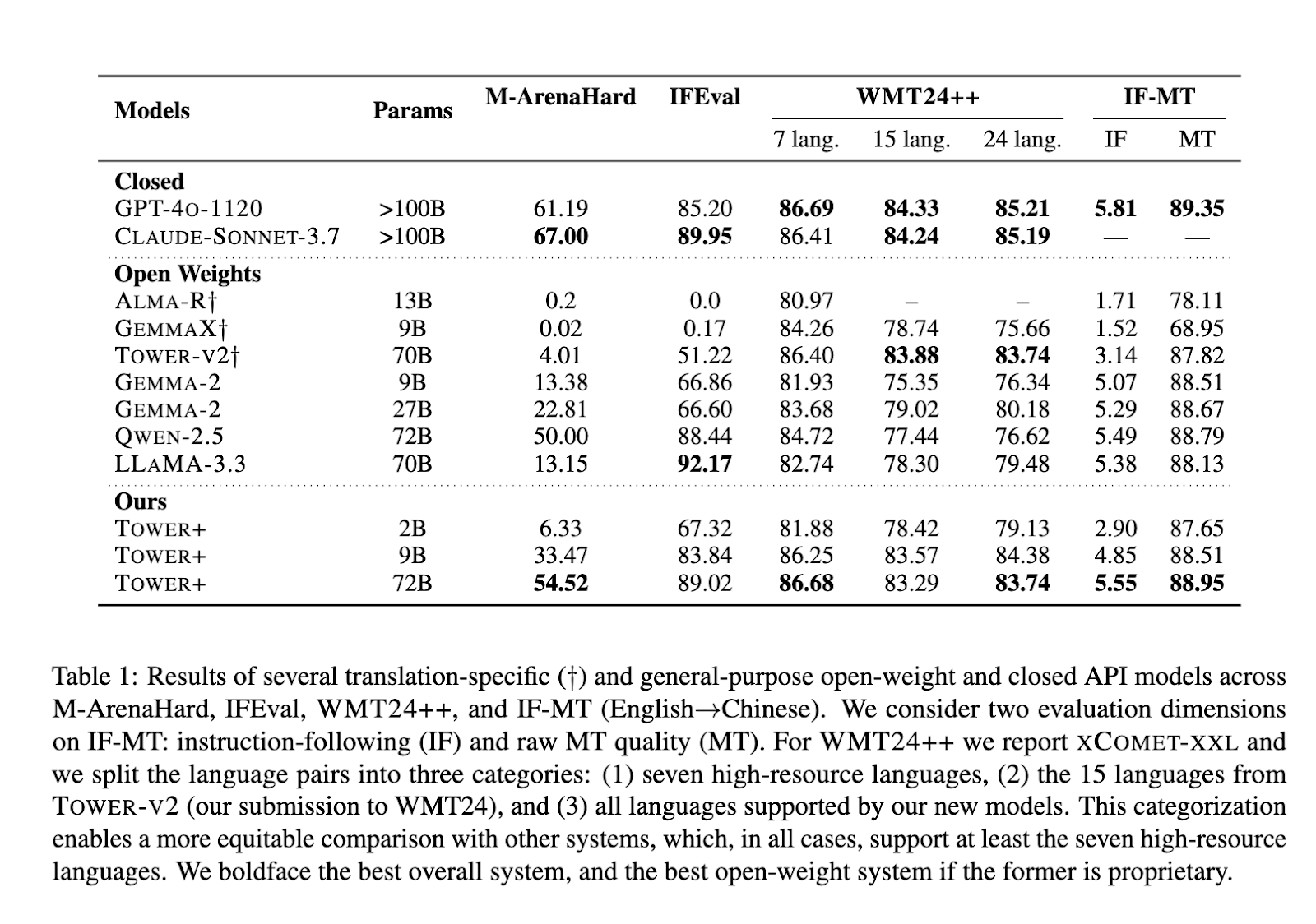
Benchmark results: Tower+ implements the latest translations and instructions
The Tower+ 9b model scored 33.47% win rate in multilingual universal chat prompts, while the XCOMET-XXL scored 84.38 in 24 language pairs, outperforming open weight pairings of similar sizes. The flagship flagship 72 billion parameter variant earned a 54.52% win rate for M-Arenahard, recorded a score of 89.02 followed by the IFEVAL instruction and reached an XCOMET-XXL level of 83.29 on the full WMT24++ benchmark standard. On the combined translation and instructions that follow the benchmark, the IF-MT scored 5.55 for instruction compliance and 88.95 translation fidelity, establishing the latest results between open weight models. These results confirm that the researchers’ integrated pipeline effectively bridges the gap between professional translation performance and broad language abilities, demonstrating their viability for enterprises and research applications.
Key technical highlights of tower+ models
- The Tower+ model is developed by unpopular and academic partners with spans of 2 B, 9 B and 72 B parameters to explore the performance frontiers between translation professionals and general utilities.
- The post-training pipeline integrates four phases: continuous preprocessing (66% monolingual, parallel 33% and 1% guidance), supervised fine-tuning (22.3% translation), weighted priority optimization and verifiable enhancement learning to maintain chat skills while improving chat skills.
- Continuous preprocessing covers 27 languages and dialects, as well as 47 language pairs, over 32 billion tokens, combining professional and general checkpoints to maintain balance.
- The 9 B variant scored 33.47% wins on M-Arenahard, 83.84% of IFEVAL and 84.38% of XCOMET-XXL scored 33.84% on 24 pairs, with IF-MT scores of 4.85 (instruction) and 88.51 (Translation).
- The 72 B model records 54.52% M-Arenahard, 89.02% IFEVAL, 83.29% XCOMET-XXL and 5.55/88.95% IF-MT, setting new open authoritative standards.
- Even the 2B model matches the larger baseline, with 6.33% of M-Arenahard and 87.65% of IF-MT translation quality.
- The Tower+ kit always matches or outperforms performance on professional and general tasks in benchmarks against GPT-4O-1120, Claude-Sonnet-3.7, Alma-R, Gemma-2 and Llama-3.3.
- This study provides a reproducible formula for establishing LLMs, which meet both translation and conversation needs, thereby reducing the proliferation and operational overhead of the model.
Conclusion: The best Pareto framework for future translation-centric LLM
In summary, by unifying large-scale pre-repairs and dedicated alignment phases, Tower+ shows that superior translation and dialogue versatility can coexist in a single open suite. These models achieve the Pareto optimal balance between translation fidelity, guidance tracking and general chat functions, providing a scalable blueprint for future domain-specific LLM development.
Check Paper and model. All credits for this study are to the researchers on the project. Also, please feel free to follow us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.



