Polaris-4B and Polaris-7B: Post-training reinforcement learning for effective math and logical reasoning
The increasing demand for scalable inference models in machine intelligence
Advanced inference models are at the forefront of machine intelligence, especially in areas such as mathematical problem-solving and symbolic reasoning. These models are designed to perform multi-step computation and logical inference, often generating solutions that reflect human inference processes. After preprocessing, reinforcement learning techniques are used to improve accuracy; however, scaling these methods while maintaining efficiency remains a complex challenge. With the increasing demand for smaller, more efficient models that still have high inference capabilities, researchers are now turning to strategies to address data quality, exploration methods, and long-term cultural generalization.
Reinforcement learning challenges for vigorous inference architecture
The ongoing problem of reinforcement learning of large-scale inference models is the mismatch between the capabilities of the model and the difficulty of training data. When the model is exposed to tasks that are too simple, its learning curve will stagnate. On the contrary, overly difficult data will flood the model and produce no learning signals. This difficulty imbalance is particularly noticeable when applying recipes that are suitable for small models. Another problem is the lack of a method to effectively adjust the elicit diversity and output length during training and reasoning, which further limits the model’s inference ability on complex benchmarks.
Limitations of existing training methods for advanced models
Early approaches, such as DeepScaler and GRPO, have demonstrated that reinforcement learning can improve the performance of small-scale inference models, which have less than 1.5 billion parameters. However, applying these same formulas to more capable models, such as Qwen3-4b or DeepSeek-R1-Distill-Qwen-7b, will only lead to marginal growth or even performance declines. A key limitation is the static nature of data distribution and the limited diversity of sampling. Most of these methods do not filter data based on model capabilities, nor adjust the sampling temperature or response length over time. As a result, they are often not able to scale efficiently when used on more advanced architectures.
Introducing Polaris: Customized recipes for scalable RL in inference tasks
Researchers at the University of Hong Kong, Orc Seeds and Fudan University introduced Polaris, a post-training recipe specifically for advanced reasoning tasks. Polaris includes two preview models: Polaris-4b-preiview and Polaris-7b-preview. Polaris-4b-preview is fine-tuned from Qwen3-4b, while Polaris-7b-preview is based on DeepSeek-R1-Distill-Qwen-7b. The researchers work to build a framework for insufficient models that modify data difficulty, encourage various explorations through controlled sampling temperatures, and extend inference capabilities by extending length inference. These strategies were developed using open source datasets and training pipelines, both models are optimized to run on consumer-grade graphics processing units (GPUs).
Polaris Innovation: Difficulty in Balanced, Controlled Sampling and Novel Inference
Polaris implements a variety of innovations. First, curate training data by eliminating problems that are too easy or unsolvable, resulting in a mirrored J-shaped distribution. This ensures that training data evolves with the growing functionality of the model. Second, the researchers dynamically adjusted the sampling temperature during the training phases of Polaris-4b and Polaris-7B for Polaris-4b and 0.7, 1.0 and 1.1 to maintain the launch diversity. Furthermore, the method uses yarn-based extrapolation techniques to extend the inference context length to 96K tokens without additional training. By implementing the “cut trains, long exams” approach, this solves the inefficiency of long-term training. The model also employs techniques such as rolling out rescue agencies and in-batch alternatives to prevent zero reward batches and ensures that useful training signals are retained, even when 8 points are kept small.
Benchmark results: Polaris outperforms larger business models
The Polaris model achieves the latest results in multiple mathematical benchmarks. Polaris-4b-preiview records 81.2% accuracy and 79.4% of AIME25 on AIME24, not even exceeding 2% of its parameters on the same task, and even exceeding QWEN3-32B on the same task. It scored 44.0% on Minerva math, earned 69.1% on the Olympic bench and scored 94.8% on the AMC23. Polaris-7b-preiview also performed well, with AIME24 scored 72.6% and AIME25 scored 52.6%. These results suggest that models such as Claude-4-Opus and Grok-3-beta build Polaris as competitive, lightweight models, thus bridging the performance gap between small open models and commercial 30B+ models.
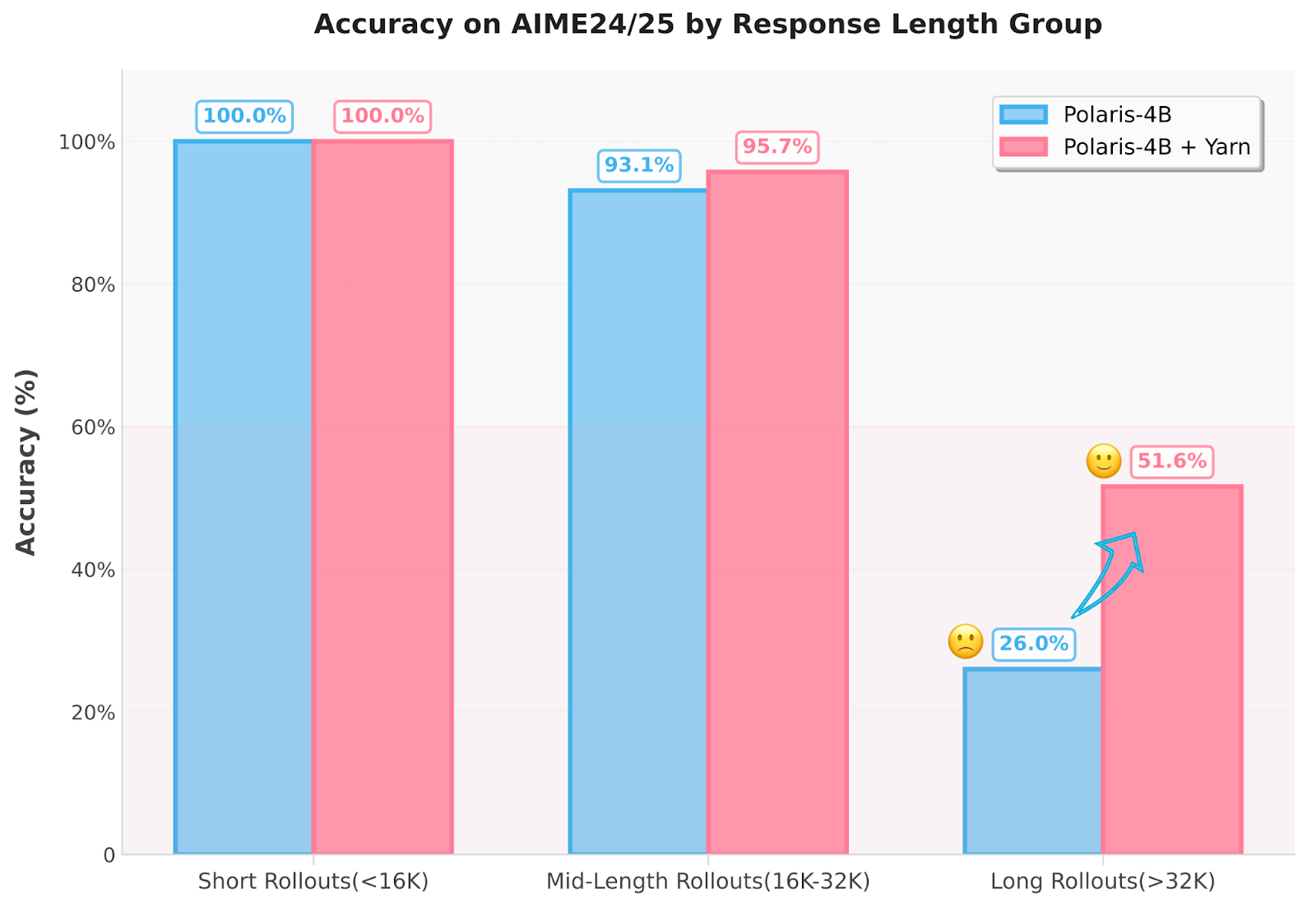
Conclusion: Effectively strengthen the strategy through intelligent training strategies
The researchers show that the key to extending an inference model is not only the larger model size, but also the intelligent control of the difficulty of training data, sampling diversity and inference length. Polaris provides reproducible recipes that can effectively adjust these elements so that smaller models can rival the inference capabilities of large-scale commercial systems.
Check Model and code. All credits for this study are to the researchers on the project. Also, please feel free to follow us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Nikhil is an intern consultant at Marktechpost. He is studying for a comprehensive material degree in integrated materials at the Haragpur Indian Technical College. Nikhil is an AI/ML enthusiast and has been studying applications in fields such as biomaterials and biomedical sciences. He has a strong background in materials science, and he is exploring new advancements and creating opportunities for contribution.



