7 LLM generation parameters – what do they do and how to tune them?
Tuning the LLM output is largely a decoding problem: you can shape the model’s next token distribution with some sampling control –Maximum number of tokens (limiting response length within the context constraints of the model), temperature (Logarithmic scaling to increase/decrease randomness), Top p/nuclear and Top k (truncate the candidate set by probability mass or rank), frequency and There are penalties (to discourage repetition or encourage novelty), and stop sequence (delimiter hard terminated). These seven parameters interact: temperature broadens the tails of top-p/top-k and then clips; penalties mitigate degradation in long generations; stop plus max tokens provide deterministic bounds. The following sections precisely define each parameter and summarize the scope and behavior of vendor records based on decoding literature.
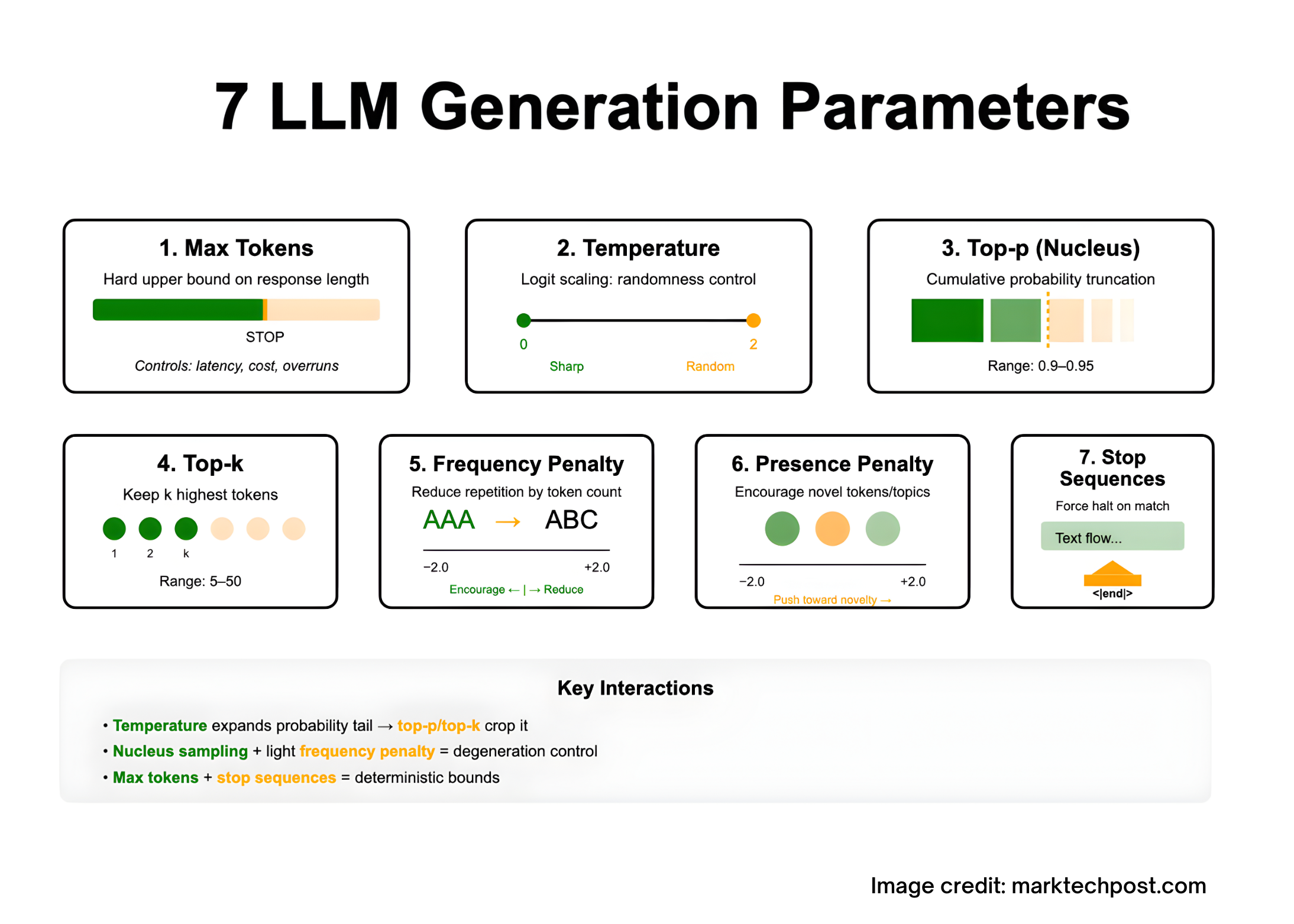
1) Maximum number of tokens (aka max_tokens, max_output_tokens, max_new_tokens)
what is it: A hard cap on how many tokens the model can generate in this response. It does not expand the context window; this and The number of input tokens and output tokens must still fit within the context length of the model. If the limit is reached first, the API will mark the response as “incomplete/length”.
When to adjust:
- Limit latency and cost (tokens ≈ time and dollars).
- Prevent exceeding delimiter when you can’t just rely on
stop.
2) Temperature (temperature)
what is it: Scalar applied to logits before softmax:
softmax(z/T)i=Σjezj/Tezi/T
reduce time Sharpened distribution (more deterministic); higher time Flatten it (more random). A typical public API exposes a scope close to [0,2][0, 2][0,2]. use Low T for analysis tasks and higher temperature for creative expansion.
3) Nucleus sampling (top_p)
what is it: Samples are only from smallest The set of tags with cumulative probability mass ≥ p. This truncates the low-probability long tail that leads to classic “degeneration” (aimlessness, repetition). Introduced as Nucleus sampling Holzman et al. (2019).
Practical notes:
- A common range of operations for open text is
top_p ≈ 0.9–0.95(hug the face guide). - Anthropic suggestion adjustments any one
temperatureortop_prather than both, to avoid coupled randomness.
4) Top-k sampling (top_k)
what is it: At each step, limit candidates to k The highest probability tags are renormalized and then sampled. Earlier work (Fan, Lewis, Dauphin, 2018) used this approach to improve novelty over beam search. In modern toolchains it is often combined with temperature or nuclear sampling.
Practical notes:
- typical
top_kTo balance diversity, the range is small (~5-50); the HF documentation shows this as a “Pro Tips” guide. - Both
top_kandtop_pSettings, applicable to many libraries k filter then p filter (Implementation details, but useful to know).
5) Frequency penalty (frequency_penalty)
what is it: Reduce verbatim repetition by reducing the probability of a token proportionally to its frequency of occurrence in the generated context. Azure/OpenAI reference scope −2.0 to +2.0 and precisely define the effect. Positive values reduce repetition; negative values encourage this behavior.
When to use: Models loop or echo long generations of wording (e.g., bullet lists, poetry, code comments).
6) Punishment on the spot (presence_penalty)
what is it: Penalize tokens that have already appeared at least once So far, models are encouraged to introduce new tokens/topics. same record range −2.0 to +2.0 In the Azure/OpenAI reference. Positive values drive novelty; negative values condense around the topics seen.
Adjust heuristics: Start from 0; nudge There is punishment Up if the model is too “on track” and does not explore alternatives.
7) Stop sequence (stop, stop_sequences)
what is it: A string that forces the decoder to stop exactly when it occurs, without emitting the stop text. Useful for limiting structured output (for example, to the end of a JSON object or section). Many APIs allow multiple stop strings.
Design tips: Pick clear Delimiters are unlikely to occur in normal text (e.g., "", "nn###"), and with max_tokens As a belt and suspender control.
important interactions
- Temperature and Nucleus/Top-k: Increasing temperature causes the probability mass to expand toward the tail;
top_p/top_kThen crops That tail. Many vendors recommend adjusting one Control randomness at a time to keep the search space interpretable. - Degradation control: As a rule of thumb, kernel sampling mitigates duplication and blandness by truncating unreliable tails. Combined with long output optical frequency penalty.
- Delay/Cost:
max_tokensis the most direct lever; streaming responses does not change the cost but improves perceived latency. ( - Model differences: Some “inference” endpoints limit or ignore these knobs (temperature, penalties, etc.). Check the model-specific documentation before migrating the configuration.
refer to:

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex data sets into actionable insights.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


